
ML4Sci #29: AI in Science; NeurIPS wrap-ups; Algorithmic Idiocy
Wrapping up 1 year of the ML4Sci Newsletter

Hi, I’m Charles Yang and I’m sharing (roughly) weekly issues about applications of artificial intelligence and machine learning to problems of interest for scientists and engineers.
If you enjoy reading ML4Sci, send us a ❤️. Or forward it to someone who you think might enjoy it!
As COVID-19 continues to spread, let’s all do our part to help protect those who are most vulnerable to this epidemic. Wash your hands frequently (maybe after reading this?), wear a mask, check in on someone (potentially virtually), and continue to practice social distancing.
Welcome to the last issue of ML4Sci in 2020! I started this newsletter on January 5, 2020 - it certainly has evolved and grown quite a lot in the past year. I have been consistently surprised both by the initiative shown by the members in this community (notice the growing number of pieces from ML4Sci subscribers!) and the strong support for more community-led platforms in ML4Sci.
As always, feel free to send me interesting papers, articles, videos, etc. related to ML4Sci or any feedback, suggestions, ideas about the newsletter and this broader community to @charlesxjyang or ml4science@gmail.com.
In the new year, I’m hoping to be sharing some work I’m doing in collaboration with a think tank to argue for the importance of AI in science funding at the federal level.
For background, I decided to play around with the Arxiv dataset on Kaggle[notebook here] to try to measure the growth of AI papers in a given science field. I denote a scientific paper as an “AI paper” if it contains any of the following words in the abstract:
['artificial intelligence','machine learning','deep learning','neural networks','neural network']I normalize the number of “AI papers” published in a given month by the total number of papers published that month, for a given field/category(see arxiv category taxonomies here). Using this obvious imperfect method of identifying “science papers that use AI”, here are some of the plots I ended up with:

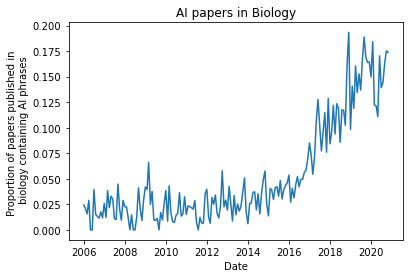

Note that all these fields start showing strong growth in the proportion of AI papers around 2016. Another interesting observation, which is probably biased by the different groups using Arxiv, is that different fields have drastically different proportions of AI papers on Arxiv right now.
The different start dates on the graph are due to setting a cutoff of at least 1000 papers published a month in a given field, to prevent noise in the normalization. Feel free to play around with the dataset more and let me know what you find! [Kaggle Arxiv dataset][my kaggle notebook]
Department of Machine Learning
💻Amazon develops its own custom AI-hardware accelerator called Trainium
NeurIPS 2020 is wrapping up and you can find all the accepted papers to the different ML4Sci workshops [ML4Molecules][ML4PhysicalSciences][ML4Engineering, Design, Simulation]
[MIT Tech Review] covers a NeurIPS paper from IBM team on an 4-bit training for neural networks architecture (as opposed to traditional 16 or 32 bits today). These kinds of techniques can help reduce the compute burden for large models, but will require new compute architectures (hence the interest from IBM). This is of interest to tech companies interested in edge compute, but also to scientists who are building ever larger AI models as well.
A new database tracking state of the art performances on hundreds of AI-tasks with datasets. Something that would be really nice to have in ML4Sci too!
📝The controversial journal Nature Machine Intelligence published its first “Reusability report”, where authors demonstrate using a previously open-sourced codebase to a novel problem. In this case, they apply 🔒conditional RNN architectures used for drug design to organic photoelectronic. Note the closed-access original paper but open-sourced code[DeepDrugCoder on github]
[Arxiv] Estimate ODE’s with uncertainty: new work on Bayesian Neural ODE’s in Julia-lang [github][h/t ML4Sci subscriber Chris Rackauckas]

Near-Future Science
An article in Crystal Engineering Communication demonstrating how to use the Cambridge Structural Database. Of particular interest are the 100,000 deposited Metal Organic Framework(MOF) structures. Open access article! (In a different life, I used to work on MOF’s a fair amount)
⛵NeurIPS presentation: Making Boats Fly with Reinforcement Learning
Blog-of-the-week: Fabian Fuchs and Justas Dauparas on the hypothesized role of equivariant transformers in the AlphaFold2 architecture aka why scientific problems will require new architectures, techniques, etc.


The Science of Science
⚕️[TheNation] Bill Gates Foundation has poured billions into the Institute for Health Metrics and Evaluation. As a result, they have compiled health data internationally that literally nobody else could have, because nobody else has the funding. Their results are also sometimes dubious, particularly when it comes to COVID-19 projections.
Reminds of OpenAI’s GPT-3 model, which won best paper award at NeurIPS 2020 this past week - a model literally nobody else (besides Facebook, Amazon, Google, and co.) could have trained
🚫[TheScientist] Top Retractions of 2020


🌎Out in the World of Tech
🏗️[TechCrunch] “AI Construction Startup Versatile raises $20M Series A”
“AI will change everything” is not a useful piece of information - but constructive examples of how people are using AI in every industry are
As a followup from last week’s [NatureNews] coverage on ethical questions facing facial recognition researchers: [WashingtonPost] “Huawei tests AI software to detect ethnic minorities”
Big movements in fighting anti-trust tech monopolies: [TheVerge] FTC+48 states sue Facebook to reverse acquisitions of Instagram, [Axios] Texas files lawsuit against Google for anti-competition in ad marketplace
Policy and Regulation
Algorithmic idiocy in vaccines, education, poverty:
🤦[NPR]Stanford uses an “algorithm” to allocate vaccines and leaves out nearly all medical residents
Continuing on that line of thought, [MIT TechReview] The coming war on the hidden algorithms that trap people in poverty”. One particular quote that stuck out:
“After a big effort to automate the state’s unemployment benefits system, the algorithm incorrectly flagged over 34,000 people for fraud. ‘It caused a massive loss of benefits,’ Simon-Mishel says. ‘There were bankruptcies; there were unfortunately suicides. It was a whole mess.’”
Algorithms are beginning to rule every part of our lives and we are not having a discussion about how/when they should be used. book rec: Weapons of Math Destruction by Cathy O’Neil is a great intro to this
Thanks for Reading!
I hope you’re as excited as I am about the future of machine learning for solving exciting problems in science. You can find the archive of all past issues here and click here to subscribe to the newsletter.
Have any questions, feedback, or suggestions for articles? Contact me at ml4science@gmail.com or on Twitter @charlesxjyang
Researchers meta-gaming the arXiv submission time is hilarious and sad at the same time
Congratz on 1 year!