
ML4Sci #34: 2 National Reports on AI in the US; Unpacking the Full-Stack of news from Facebook this week
Also, new interpretability methods+adversarial attacks on Neural Networks from OpenAI

Hi, I’m Charles Yang and I’m sharing (roughly) weekly issues about applications of artificial intelligence and machine learning to problems of interest for scientists and engineers.
If you enjoy reading ML4Sci, send us a ❤️. Or forward it to someone who you think might enjoy it!
📝Nationalized AI Reports
Two big national reports on AI from the US came out this week.
The first is the National Security Council on AI, chaired by Eric Schmidt, former CEO of Google, which submitted its final report and set of recommendations to Congress. This comprehensive report is the best overview of where America, particularly its defense base, is heading in terms of AI. Here’s a brief list of some of the snippets that stood out to me:
the US should strive to “achieve a state of military AI readiness”[military] and “widespread integration of AI”[broader economy] by 2025
does not rule out the use of autonomous weapons: “Provided their use is authorized by a human commander or operator, properly designed and tested AI-enabled and autonomous weapon systems can be used in ways that are consistent with international humanitarian law.”
recommend the creation of a US Digital Service Academy
an entire chapter on “Establishing Justified Confidence in AI Systems”, which focuses on verification and robustness of AI systems
recommending significant immigration overhaul, including doubling number of employment green cards, creating an entrepeneur visa, and giving green cards to graduates of STEM doctoral programs
recommend a tightening of export controls for dual-use technologies and applications
Meanwhile, the other side of the country, HAI@Stanford released its annual AI Index, which measures AI progress and trends. Some highlights:
34% growth in AI papers from 2019-2020, outpacing the change from 2018-2019
The majority of US PhD students in AI chose to work in industry after graduating, as opposed to academia
Less than 6% of US PhD students in AI are African American or Hispanic
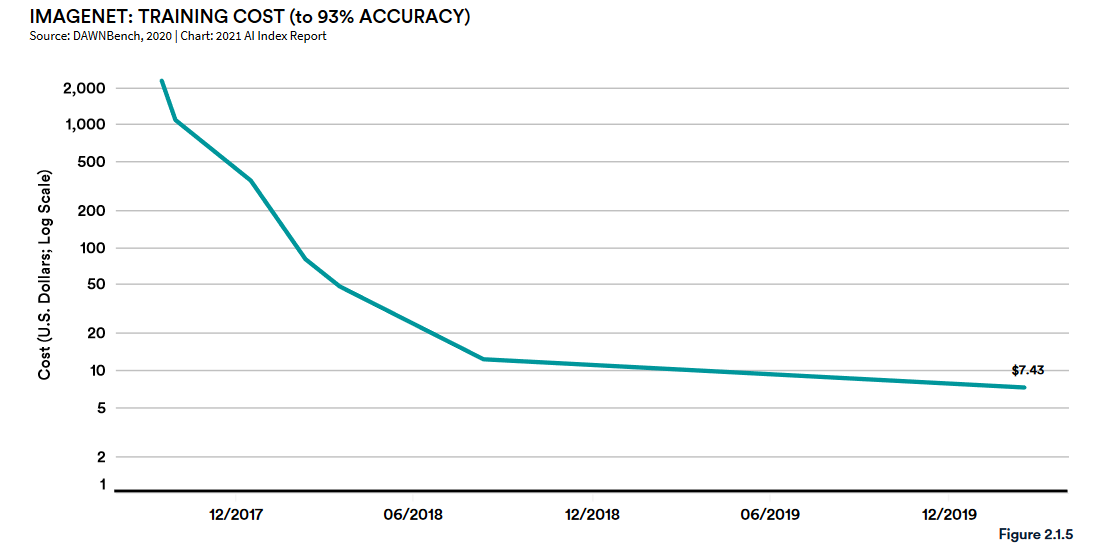
To reach roughly human accuracy on ImageNet now only requires $7.43 of compute
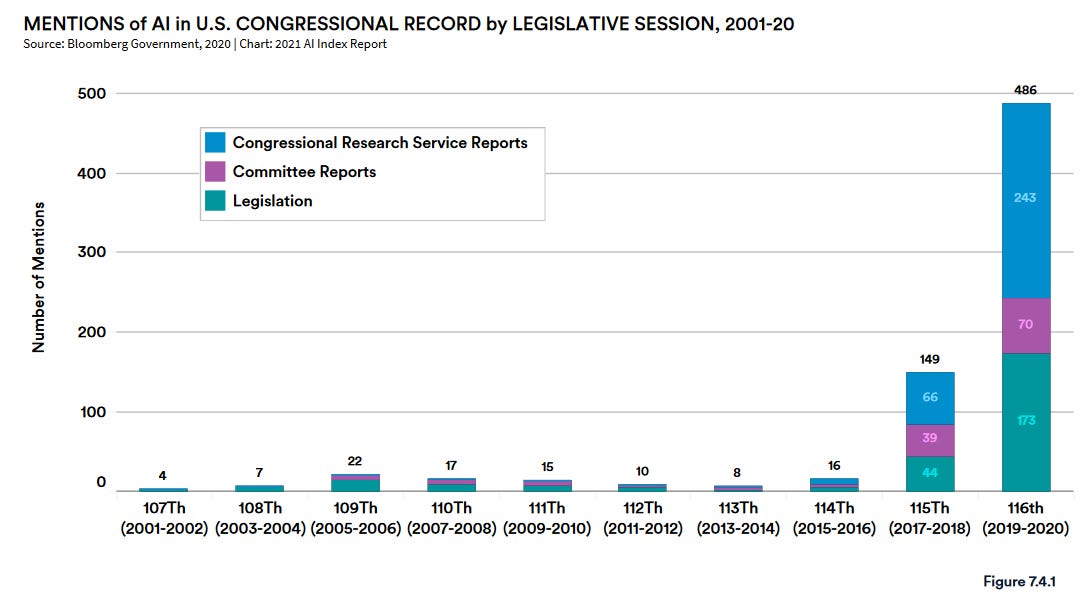
AI has captivated the attention of the US Congress
And a nice quote on the push and pull between NLP and CV progress:
“It’s interesting to note the dominance of the Transformers architecture, which started for machine translation but has become the de facto neural network architecture. More broadly, whereas NLP trailed vision in terms of adoption of deep learning, now it seems like advances in NLP are also driving vision.” —Percy Liang, Stanford University (Chapter 2, Expert Highlight)
Unpacking the Facebook stack
A significant portion of advanced AI research is now being done by pseudo-research groups hosted at large tech companies, which usually derive their revenue from attention economics i.e. ads. The past two weeks, I’ve come across the full-stack of news from Facebook - ranging from new cutting-edge AI techniques in self-supervised computer vision to a new indicting article from MIT Technology Review on how Facebook has failed to address concerns about its social recommendation engine. It’s pretty crazy to think that AI is being developed by people who are funded by a company that also has to create a playbook for employees to explain why the company they work for is not destroying America.
In Research: The Facebook AI team develops a powerful unsupervised image recognition algorithm called SEER (they also published this broader blog on the increasing importance of self-supervised learning, which is worth reading), which reaches a new SOTA on self-supervised training for ImageNet. Advances in contrastive learning for computer vision mean that CV models can now learn from the vast unlabelled image data on the web, in a similar fashion to NLP models.
In regulation: this algorithm was probably trained on your instagram photos! Unless of course, you live in Europe, in which case your data was protected by GDPR. These issues of sovereignty, data provenance, and privacy are starting to seriously impact the way large tech companies develop algorithms - I wonder if SEER is biased against European images because of a lack of data?
In academia: The University College London’s CS department is deeply entangled financially with Facebook - the tech monopolization of AI academics continues
In society: Karen Hao at MIT Tech Review does a deep dive on AI at Facebook, nicely tying together the people, the algorithms, and the business models that have created the Facebook we have today.
And now, for the news!
Department of Machine Learning
[Distill] Incredible visualizations of “multimodal neurons” in neural networks by an OpenAI team. Their evidence for multimodal neurons also inspired new adversarial attacks:
A nice overview of graph neural networks and the limitations of the current message-passing paradigm
🤖Folding clothes is a surprisingly hard benchmark - researchers from Berkeley demo demonstrate a real-world system that can actually fold different fabrics [video]
Near-Future Science
🏆The Department of Energy’s Solar Energy Technology Office (SETO) announces $7.3M in awarded funding for AI solutions - awardees are mostly universities, national labs, and the startup Camus Energy
🪐How the Perserverance Mars Rover used AI to navigate and land
More exciting work on equivariant deep learning, which demonstrates SOTA and sample efficiency on molecular simulations tasks. See 👇 for a paper-in-a-thread


The Science of Science
💻[NatureNews] A poll of researchers showed that a strong majority prefer some form of virtual conferences in the future. There’s a huge opportunity here for a platform that can provide the ease of digital conferences while reproducing the spontaneity of in-person conferences. Virtual conferences also have the benefit of being more accessible, cheaper, and significantly reduce carbon emissions from air travel
new-journal-alert: Living Journal of Computational Molecular Science, a journal that essentially lives on Github. Software is finally starting to change the way we view scientific publishing, from static articles to living journals (with pull-requests too!)
🌎Out in the World of Tech
blog-of-the-week: “7 reasons not to join a startup and 1 reason to” from Chip Huyen, formerly at Snorkel
🏥 Commercializing AI is hard: IBM is considering selling off its IBM Watson Health business. Recall late last year that Alibaba also shut down its AI lab and Canada’s Elemental AI was sold-off at a fairly devalued pricing
The good and bad from Google:
- backlash against Google continues after they fired the leads of their AI Ethics team: [VentureBeat] “AI ethics research conference suspends Google sponsorship”.
- 🌞 but Google Cloud announces a new method for certifying clean energy that focuses on time-of-use. This is an important step forward for companies that are trying to decarbonize because it rewards developers of energy systems that can complement renewables that are only available during at certain times of day e.g. solar.
Policy and Regulation
🕵️ The UK’s GCHQ (basically their NSA) releases a white paper embracing the use of AI in intelligence applications. emphasizing the importance of AI ethics.
Thanks for Reading!
I hope you’re as excited as I am about the future of machine learning for solving exciting problems in science. You can find the archive of all past issues here and click here to subscribe to the newsletter.
Have any questions, feedback, or suggestions for articles? Contact me at ml4science@gmail.com or on Twitter @charlesxjyang