
ML4Sci #6: Neural Message Passing for Quantum Chemistry; Language Modeling for Protein Sequences; AI for diagnosing COVID-19 from Chest CT Scans
Also, more COVID-19 and science coverage, plus some tweets from Geoff Hinton

Hi, I’m Charles Yang and I’m sharing (roughly) weekly issues about applications of artificial intelligence and machine learning to problems of interest for scientists and engineers.
If you enjoy reading ML4Sci, please hit the ❤️ button above. Or forward it to someone who you think might enjoy reading it!
As COVID-19 continues to spread, let’s all do our part to help protect those who are most vulnerable to this epidemic. Wash your hands frequently (maybe after reading this?), check in on someone (potentially virtually), and continue to practice social distancing.
Neural Message Passing for Quantum Chemistry
published June 12, 2017
Another Google paper. *Insert standard commentary about unknown consequences of tech companies dominating the space of ML4Sci*
This paper establishes a general framework for training neural network models to take molecules as input and predict their associated properties. Molecules most naturally conjure up the ideas of graphs, so the authors examine different graph neural network models proposed in literature and demonstrate how all these different models fit within a framework they refer to as “message passing neural networks” (MPNN).
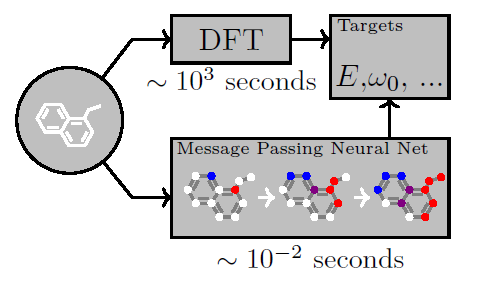
What exactly is a MPNN? Loosely, it’s where (1) each node passes “messages” to all its neighbors and (2) each node has a hidden state it updates based on its previous hidden state and all the messages it receives from its neighbors. After some set number of rounds of message passing, a “read-out” function takes all the hidden states and outputs a prediction. With this general framework, they implement a MPNN model that achieves state-of-the-art (SOTA) on the QM9 dataset, which has 130K small organic molecules and 13 different molecular properties (such as HOMO, LUMO levels, dipole moment, vibrational frequency, atomization energy etc). For metrics, they add in the idea of “chemical accuracy”, which is a quantification of how accurate the numerical model’s “ground-truth” label is, to account for the fact that some quantities are known to be more numerically accurate than others. For instance, band gap is notoriously difficult to calculate accurately from DFT.
This high-impact work (>800 citations) is a good example of how scientific problems have unique problem types (e.g. speeding up numerical simulations), require novel model architectures (e.g. adapting graph neural networks for molecules), and have non-intuitive metrics (cat and dog labels are pretty easy to verify; numerical simulations not so much).
[pdf][github][google blog]
ProGen: Language Modeling for Protein Generation
Published March 17, 2020
A paper by Salesforce’s Einstein AI team (+Stanford). Yes, Salesforce is a Customer-relationship management company. Yes, they have a deep learning research team.
The motivating observation for this paper is that there “are three orders of magnitude” more protein amino acid sequences than there are structural annotations for proteins. In other words, its much easier for us to determine the amino acid(AA) sequence of a protein than the actual 3D folding structure. This is true both experimentally and computationally. Because the properties of a protein are fundamentally tied to its 3D structure, this makes it difficult to engineer proteins with desirable properties. The experimental solution to this has been directed evolution, an idea which won the 2018 chemistry nobel prize. Computationally, some people have tried applying deep learning to speeding up the mapping from AA-sequence to 3D configuration, like the friendly folks over at Google, whose AlphaFold work we covered in ML4Sci #3. But this paper skips the 3D configuration step and tries to generate AA-sequences conditioned directly on the associated protein properties e.g. function and cellular location, treating AA-sequences as if it were a 22-character language.
Using a 1.2B transformer-based model, they train on 280M AA-sequences, drawn from 6 different datasets. This makes it the largest known NLP approach to protein sequences and comparable to some of the largest NLP models. It took 2 weeks to train this monster on 256 Google TPU’s. For comparison, OpenAI’s heavily covered GPT-2 model was 1.5B parameters.
Using the trained model, the authors are able to generate AA-sequences by conditioning on desired properties. They add a repetition penalty to penalize sampling AA’s that were predicted already suggested earlier in the sequence. This repetition penalty seems to be a new idea in NLP text-generation and a similar cohort of authors from this paper have published another NLP work demonstrating it in a more traditional NLP context.
Evaluating generative models was (and still is) a fairly difficult and non-intuitive problem. This paper takes some interesting approaches to metrics because of the domain knowledge associated with AA-sequences, again demonstrating how the accompanying scientific context can shape model development. In this case, they use a variety of methods, including an AA substitution matrix, which is similar to a character frequency table, monte-carlo energy relaxation calculations to compare different AA-sequences conformational energy, and comparing their generative model to mutation-based models.
[pdf][Salesforce blog][h/t Import AI #189]
AI distinguishes between COVID-19 and Pneumonia from Chest CT Scans
Published in March 19, 2020
Coming from researchers in China, this work uses a convolutional neural network to classify 3D chest CT scans, including those with COVID-19. With 4,356 scans from 3,322 patients, 30% of the scans were diagnosed COVID-19, 40% with unrelated pneumonia, and 30% were healthy scans. The non-COVID-19 scans were obtained between 2016-2020. Their architecture was a Resnet-50 with U-net semantic segmentation for preprocessing, achieving a 95% AUC score. To improve interpretability, they use gradient-weighted class activation mappings to visualize which local areas the CNN is focusing on to make predictions.
The authors are (in my opinion, appropriately) qualifying in their discussion, noting that their dataset did not include viral pneumonia, which may have cause similar lung damage to COVID-19, as well as the lack of population control e.g. age, co-morbidities on their sample. While clearly a rushed publication, the present circumstances certainly help make it relevant.
New challenges present an opportunity to test new technologies. COVID-19 has proven to be a testing ground for many new technologies, especially computational modelling, while also highlighting challenges in how we communicate science to the public.
COVID-19 and Science
The DOE and NSF have both pivoted resource allocation toward tackling the COVID-19 epidemic. In particular, we’ve seen the opening up of supercomputer resources for biological modelling of COVID-19 research.


How Trump’s crackdown on foreign funding of researchers is affecting us now in the COVID-19 outbreak. An interesting coincidence that one of the 3 scientists who has left the US as a result of FBI investigation into improper reporting of foreign funding is now developing COVID-19 testing in China. Another glimpse into how science is increasingly straying into international politics, as global economies compete for market dominance various tech sectors.
The rise of the Coronavirus influencer by Buzzfeed. The problem of inscrutable scientific writing meets a public health crisis. As science becomes more complex yet increasingly relevant to our daily lives e.g. AI, how do we communicate information quickly and accurately? Even scientists are having trouble keeping up with new developments, as the rate of new published papers in certain hot fields is more like a flood (GAN’s are a good example, COVID-19 papers are another).
Folding at Home is a Stanford research project that leverages crowd-sourced distributed computing (read: anyone with a laptop and internet) to help calculate protein dynamics for various diseases, including COVID-19. They’ve reported a cumulative 474 petaFLOPs of computing power, which is twice the computing ability of Summit, the world’s largest supercomputer at Oak Ridge National Lab (ORNL). Incidentally, researchers at ORNL just released a preprint where they use Summit to identify pre-existing therapeutic molecules that disrupt the hypothesized protein receptor COVID-19 uses.
Finally, from Geoff Hinton’s twitter on AI in medicine:

Some responses:





Some important things to note: what does it mean if a model is explainable? Human doctors may be biased, but models are biased in their own, more subtly hidden ways. How do we verify that the model is generalizable to the entire population? How do we distribute blame and thereby ensure trust in a medical life-and-death context?
What do you think? Feel free to leave a 💬 on what you think!
Thank You for Reading!
I hope you’re as excited as I am about the future of machine learning for solving exciting problems in science. You can find the archive of all past issues here and click here to subscribe to the newsletter.
Have any questions, feedback, or suggestions for articles? Contact me at ml4science@gmail.com or on Twitter @charlesxjyang