
ML4Sci #15: News from the World of Open Science; Bayesian Experimental Autonomous Researcher for Mechanical Design; Learning Graph Models for Template-Free Retrosynthesis
Also: a new randomized trial shows that tweeting can boost a paper's citations by 4x

Hi, I’m Charles Yang and I’m sharing (roughly) weekly issues about applications of artificial intelligence and machine learning to problems of interest for scientists and engineers.
If you enjoy reading ML4Sci, send us a ❤️. Or forward it to someone who you think might enjoy it!
As COVID-19 continues to spread, let’s all do our part to help protect those who are most vulnerable to this epidemic. Wash your hands frequently (maybe after reading this?), check in on someone (potentially virtually), and continue to practice social distancing.
News from the World of Open Science
A follow-up to my essay on COVID-19 and scientific gatekeeping from ML4Sci #12 based on some recent news
Moving to Open Access
Last year, the University of California announced the suspension of negotiations with publishing giant Elsevier, which includes Scopus and ScienceDirect in its product lineup, due to disagreements about open source and publishing costs. As the first, and largest, US university system to do so, the UC system follows the example of several other major European institutions like the Max Planck Institute in ending their publishing contract with Elsevier over issues about open access.
Last week, I shared with readers of ML4Sci that MIT followed the UC system in ending their contract with Elsevier due to similar concerns over lack of open access.
And now, this week, the UC system announced that they had reached a “transformative open access publishing agreement” with Springer Nature, which includes the prestigious family of Nature journals, and is second to Elsevier in terms of size.
What does open publishing have to do with ML4Sci? Well, one arguable driver of innovation is rapid, dissemination of research results. In the heady early years of the 2010’s, it seemed like every other month saw a new, breakthrough deep learning trick. Part of this was enabled by the rapid preprint publishing, that allowed researchers to build off the latest work and share new ideas or training paradigms. It also lowered the barrier of entry for anyone with a computer and internet to learn, and even implement, the cutting edge of deep learning models.
The high financial cost, inefficient review process, and slow dissemination process that plagues current journal publishing stands in stark contrast to the fast turnaround of ML conferences. To spur innovation in the sciences, we need to look to the faster, biannual conference schedule in ML and the preprint + rapid, open review process. To be sure, there are also problems with these approaches, but I’m confident there is some optimal in-between journal publishing, conferences, and preprint servers.
Who should start exploring these new publishing paradigms? Well, ML4Sci is a great field to start - living at the interface of two fields allows for the creation of new cultures and structures, while at the same time considering the intrinsic differences of scientific experimentation vs. pure ML. The encouraging steps by the UC system and MIT, as well as their European counterparts, signal the start of the coming tectonic shifts in scientific publishing.
🐦Twitter and scientific impact
On a slightly different note, an article published this week showed in a randomized study of thoracic surgery articles that tweeting significantly boosts the number of citations for a paper.


I mentioned above that there are problems with preprint servers: this is one of them. When we lack robust peer review and well-designed forums for back-and-forth, we end up with a flood of paper verified by “academic twitter”.
Social media is not a plausible alternative for peer review, and yet its pervasiveness in our society is affecting the way we do science, and this paper provides concrete evidence of that. Indeed, in this case, social media seems to be shortcutting or supplementing peer review in a way that is most likely creating a “rich get richer” effect. Well-established groups probably have well-established Twitters->their papers have broader reach and citations->such groups become even more well-established.
In my essay from several weeks ago, I argued for the importance of a diverse set of gatekeepers, who are informed aggregators and disseminators of broad scientific knowledge, as the alternative to “academic twitter”. I would argue that this paper further highlights the danger of “socializing” science into likes and retweets, as opposed to encouraging open and cogent discussion. These are still early days and we still lack the platforms to do this but there are several new, promising efforts to build such infrastructure.
A Bayesian experimental autonomous researcher for mechanical design
Published on April 10, 2020
Much of ML4Sci research has focused on accelerating the search over numerical simulations. This work is exciting because it uses bayesian modelling to explore the 3D printing design space experimentally (as opposed to in simulation). The automated experimental setup is shown below, with 6 3D printers, a mass scale, an automated mechanical testing machine, and a robot arm to move samples from the printer to the testing stations.

(i) five dual extruder fused deposition modeling (FDM) printers, (ii) a six-axis robotic arm, (iii) a scale, and (iv) a universal testing mechanical machine
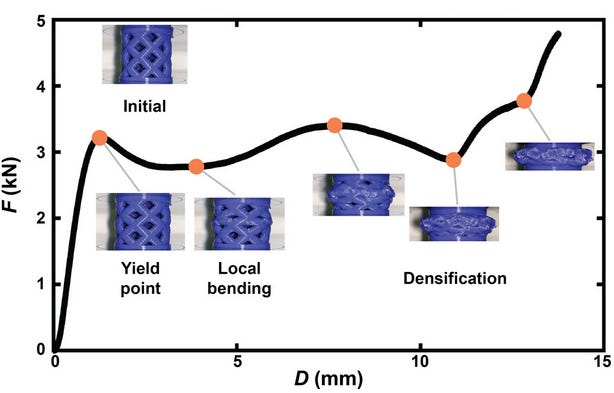
The motivation for this project is to develop 3D printed structures with high toughness without exceeding a given force threshold, which is desirable in applications like car crumple zones, where we want to maximize the energy absorbed the crumple zone while minimizing the force transmitted to the passengers. For this paper, the authors explore the crossed barrel design, which is parameterized by 4 values.
The authors begin with a useful control study, by having the 6 printers synthesize the same design to measure the quality control of the designs. As I’ve mentioned previously, 3D printers are actually complex control systems and optimizing their printing parameters to reduce defects is an open problem.
A brute-force grid search is compared with various bayesian optimization (BO) algorithms for active learning. The BO algorithms used are pure exploration (PE) (random), maximum variance (MV), and expected improvement (EI). The authors demonstrate a 60-fold reduction in number of prints required to reach an optimal design and also do some testing to elucidate design principles from the optimal design (shown below).
[paper]
Learning Graph Models for Template-Free Retrosynthesis
Published on June 12, 2020
“Retrosynthesis prediction… attempts to identify a series of chemical transformations for synthesizing a target molecule”
Retrosynthesis is an important field of study for organic molecule synthesis (e.g. synthesis of pharmaceutical compounds). This approach from researchers at ETH Zurich and MIT uses a novel graph-based message passing neural network (which we covered in ML4Sci #6) that achieves state of the art performance on a US Patent Trade Office (USPTO) dataset of molecular reactions.
“We first derive suitable building blocks from the product called synthons, and then complete them into valid reactants by adding specific functionalities called leaving groups. These derivations, called edits, are characterized by modifications to bonds or hydrogen counts on atoms”.
In short, message passing neural networks are used to obtain continuous vector-valued representations of atoms in a molecule. They then train two separate neural networks to transform these vector-valued representations into edit distance and synthons. These networks can be trained independently or with a shared encoder. To identify reaction products, they use beam search, which is essentially a greedy, depth first search algorithm, based on the synthons and edit distance.
Overall, this paper is a nice demonstration of how previous advances in using deep learning for molecular modeling e.g. message passing neural networks, are now driving advances by building more complex models on top of these architectures. This kind of evolution is reminiscent of the pattern of deep learning research: basic architectures (e.g. CNN, transformers) lead to more advanced models (GAN’s for image synthesis, BERT).
[paper]
📰In the News
ML
ICML 2020 Workshop: ML retrospectives. “Think about how you talk about your research when writing a paper.” (Pause for a second.) “Now, think about how you’d talk about your research to a good friend who wanted to build on it.”
Google at Computer Vision, Pattern Recognition (CVPR) 2020 conference
Science
From Jack Kelly’s OpenClimateFix: why we need open sharing protocols for energy systems
A git repo of “Literature of deep learning for graphs in Chemistry and Biology”
The Science of Science
Visualizing how papers are connected
Global AI Talent Tracker from MacroPolo [NYT’s coverage of this project]. Google is by far the institution with the greatest concentration of top AI talent
🌎Out in the World of Tech
A summary of recent US AI Legislation from CSET@Georgetown
GitHub abandons 'master' and 'slave' terms
Long Read: Why does DARPA work?
Thanks for Reading!
I hope you’re as excited as I am about the future of machine learning for solving exciting problems in science. You can find the archive of all past issues here. If someone forwarded you this email or shared it with you, consider subscribing!
Have any questions, feedback, or suggestions for articles? Contact me at ml4science@gmail.com or on Twitter @charlesxjyang