
ML4Sci #7: Exascale Deep Learning for Scientific Inverse Problems; Learning Fluid Mechanics; MetNet: Another weather model from Google
2 new weather models from Google in 2 months and why this is important

Hi, I’m Charles Yang and I’m sharing (roughly) weekly issues about applications of artificial intelligence and machine learning to problems of interest for scientists and engineers.
If you enjoy reading ML4Sci, please hit the ❤️ button above. Or forward it to someone who you think might enjoy reading it!
As COVID-19 continues to spread, let’s all do our part to help protect those who are most vulnerable to this epidemic. Wash your hands frequently (maybe after reading this?), check in on someone (potentially virtually), and continue to practice social distancing.
Exascale Deep Learning for Scientific Inverse Problems
published September 24, 2019
Training extremely large models i.e. those that can’t fit in a single GPU, is challenging because of the overhead of distributing and collecting gradients from different workers. Scientists at the Oak Ridge National Lab used the Summit supercomputer to demonstrate a training scheme that achieves near linear scaling of massive deep learning models on 27,600 NVIDIA V100 GPU’s.
They demonstrated their scaling capabilities by training a modified fully-convolutional dense neural network to solve the inverse Schrodinger equation. The Schrodinger equation maps electron densities to a diffraction pattern. However, we are usually interested in the inverse problem: given some diffraction pattern, I would like to know the electron density. But the mapping is not 1-to-1 because diffraction images return the norms of the Schrodinger equation, we lose half of the information i.e. the complex-value, which is referred to as the phase problem. This is referred to as the inverse phase problem and also appears in medical imaging and microscopy.
The authors simulate the electron diffraction patterns of 60,000 materials, resulting in a total of 400,000 different crystal systems, using ~100,000 atoms for each system. Benchmarking the models performance is difficult simply because nobody else has been able to sucessfully run a model on this difficult of a problem, but they show nice qualitative images of reproducing electron densities. Being able to efficiently train deep learning models at supercomputer scales is another step step in the “industrialization of AI”, one that will be critical for pushing ML4Sci to commercial applications and widespread usage.
Hidden Fluid Mechanics🔒
Published February 28, 2020
Experimental fluid mechanics often measures some scaler property in a fluid field (dye or colored smoke) but extracting relevant properties about the fluid flow (velocity or pressure) is difficult. This new work by Maziar Raissi et. al. trains a neural network to extract these parameters given only the scaler property evolution by tuning the loss function, shown below. The first term trains the NN to predict the evolution of the scaler property, while the second term forces the NN to minimize the residuals from the Navier-Stokes equations (transport equation, momentum, continuity conditions). Because Navier-Stokes equations are partial differential equations, these residuals are easily incorporated into autograd software like Pytorch for backpropagation.
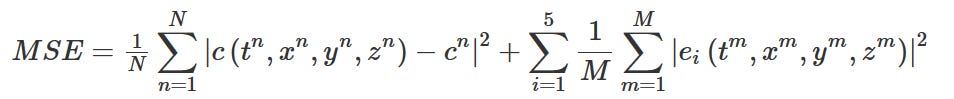
Intuitively, the first term in the loss function is the standard loss function for time-series forcasting, while the second term is incorporating domain knowledge (via Navier-Stokes) and forcing the NN to also learn the relevant fluid dynamics components. One important advancement is that their model is independent of boundary conditions, allowing this technique to be applied to any fluid flow problem. They showcase their model on a standard 2D cylinder flow problem and a 3D intracranial aneurysm.
Maziar Raissi, now a professor at University of Colorado - Boulder, has done a lot of work in the past three years in the intersection of solving partial differential equations (PDE) and deep learning. The general idea is quite similar to the one shown above: use the fact that PDE’s are differentiable and regularize the loss function with information provided by the PDE. Some of his most canonical work on the subject is here:
Physics Informed Deep Learning (part 1) (arxiv)
Physics Informed Deep Learning (part 2) (arxiv)
Deep Hidden Physics Models (JMLR)
Raissi worked at NVIDIA for around a year after finishing his post-doc at Brown University and before starting as a professor. NVIDIA, like Google, and Salesforce, is heavily investing in ML4Sci. In NVIDIA’s case, they want to make sure their hardware is the first choice for computationally intensive scientific problems, many of which are being accelerated by deep learning models on GPU’s. They’ve done this, not only by developing their own deep learning research team, but by releasing nice GPU software abstractions to help speed up scientific calculations (and deep learning training in general). Jensen Huang, NVIDIA’s CEO, demonstrated the work from this paper at a recent supercomputing conference. Expect it to be one of many NVIDIA and academia collaborations, as they try to ensure scientists think of NVIDIA first when considering computing hardware for scientific computations.
[🔒pdf][preprint][code][NVIDIA blog]
Another Weather Model from Google
Published March 25, 2020
Building off of previous work from 2 months ago, which we covered in ML4Sci #2, Google released MetNet, a neural network for weather forecasting. Their model is able to predict “future precipitation at 1 km resolution over 2 minute intervals at timescales up to 8 hours into the future” and “outperforms the current state-of-the-art physics-based model in use by NOAA for prediction times up to 7-8 hours ahead and makes a prediction over the entire US in a matter of seconds as opposed to an hour”. You can find another nice, readable, Google blog post on their work here.
Their new model surveys a 1024x1024km square to make a prediction for a single 64x64km square, with 1km resolution. The past 90 minutes of observed data are fed into a convolutional LSTM and a spatial aggregator that used axial attention. This model outperforms NOAA’s current weather model and also provides probabilistic forecasts rather than a fixed output unlike most numerical models.

This work achieves a much longer forecasting time-frame than their previous nowcasting work, which only provided forecasts up to 90 minutes in advance. It’s easy to see why: their nowcasting paper used a convolutional U-net, which isn’t particularly suited to capturing long-term temporal effects; but in this work, they utilize convolutional LSTM, as well as a larger input region for a given smaller output region.
Why do we care?
Why is Google investing in weather prediction (and why do I keep talking about it)? I imagine it’s because Google is hedging their bets that accurate, real-time weather forecasting will become increasingly important in the coming decades, as a result of a confluence of trends such as increasing renewable energy penetration (which is highly variable and dependent on the weather) and the growing importance of climate and extreme weather forecasting, as well as more traditional interests, such as agriculture and business sales forecasting. Google is betting that they can do better than traditional weather forecasters, by leveraging their expertise in AI and massive compute abilities, and that there are industries out there who will pay for it. As their most recent work shows (and their previous paper from 2 months ago), they are making rapid progress.
Traditionally, weather forecasting was a public good, provided by government agencies, and freely available to all. After all, who else but the government could place weather satellites into space, run supercomputers to analyze the data, and publicize these forecasts to news agencies? But in an age of AI, abundant satellite data, and a growing financial demand for accurate, real-time weather forecasts, private companies like Google are moving into this space. It’ll be interesting to see whether NOAA tries to adapt and incorporate these AI models, essentially competing with Google, or give up and just become a public data provider.
I’m imagining in the near future that Google will release an API service where companies can pay to access accurate, real-time weather forecasts for metrics like precipitation, cloudiness, and even wind-speed. Perhaps this will be the first instance of the new AI-powered SaaS: Science-as-a-Service. I’m hoping to flesh out this idea more in the coming weeks - stay tuned!
[pdf][Google blog]
Quick Reads
AI Currents from Azeem Azhar and Libby Kinsey: A fairly non-technical, yet comprehensive, overview of AI advancements in the past year
Finally, for anyone who’s using this extra time at home to reflect on their research or wondering what life in a ML research/PhD looks like, here are some classic guides to ML research:
An opinionated guide to ML Research by John Schulman, founding member of OpenAI
A survival guide to a PhD by Andrej Karpathy, previously a moderately famous Stanford CS PhD student, now Director of AI at Tesla
Interested in hearing more about what ML research looks like in the real-world? Check out our previous coverage of Airbnb’s deep learning team’s experience in building a neural network based search engine.
Thank You for Reading!
I hope you’re as excited as I am about the future of machine learning for solving exciting problems in science. You can find the archive of all past issues here and click here to subscribe to the newsletter.
Have any questions, feedback, or suggestions for articles? Contact me at ml4science@gmail.com or on Twitter @charlesxjyang