

ML4Sci #9: AutoML discovers new normalization-activation layer; Ph.D Thesis on Inverse Design for Photonics
Why computer vision may be overfitting as a field and how ML4Sci can help

Hi, I’m Charles Yang and I’m sharing (roughly) weekly issues about applications of artificial intelligence and machine learning to scientific and engineering problems.
If you enjoy reading ML4Sci, please hit the ❤️ button above. Or forward it to someone who you think might enjoy reading it!
As COVID-19 continues to spread, let’s all do our part to help protect those who are most vulnerable to this epidemic. Wash your hands frequently (maybe after reading this?), check in on someone (potentially virtually), and continue to practice social distancing.
AutoML discovers new neural network normalization-activation layers
Published April 6, 2020
Neural architecture search(NAS) is a growing subfield of deep learning research that promises the ability for researchers to upload a dataset and NAS will automatically discover the best neural architecture for your problem. Indeed, Google Cloud already has AutoML solutions (though their efficacy is quite untested). The important semantic difference between NAS and this paper is that NAS promises task-specific architecture optimization while this most recent paper, titled “Evolving Normalization-Activation Layers”, is framed as the first step toward algorithms that can discover generalizable, task-independent, neural network layers that are better than human-designed ones. This work builds off of previous work by the same group at Google dubbed automl-zero, which demonstrated a search algorithm able to, from basic mathematical operations, develop models that mimic simple neural networks with SGD. The figure below is from the automl-zero paper that displays the search algorithms progress at re-discovering different machine learning algorithms.
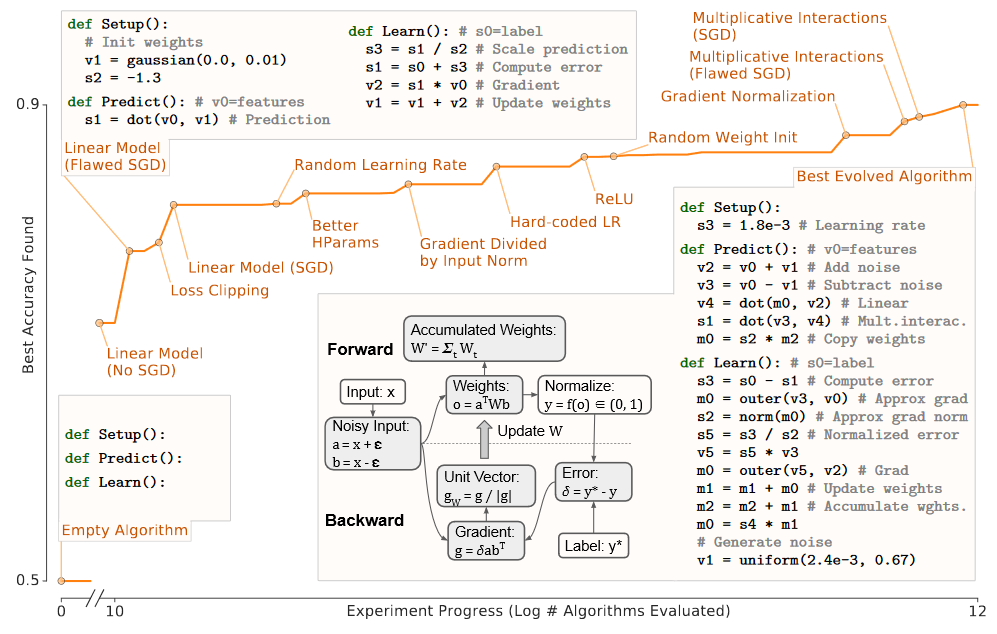
This new paper proposes to use an evolutionary algorithm similar to the one used in automl-zero to co-evolve the normalization+activation layer. The current best pairing of normalization-activation layers is batchnorm+ReLU, but both were independently developed over years of human fine-tuning. The hypothesis of this paper is that by co-evolving them together, they might find a normalization+activation layer that outperforms those independently developed by humans over many years. See the table below for the list of primitive operations used to define a computation graph of the normalization+activation layers. They term their new normalization+activation layer EvoNorm and show that it gives slight performance boost on both CIFAR and ImageNet with 3 different architectures of models.

NAS, which promises automated task-specific neural architecture discovery, and more general AutoML, which promises task-independent neural architecture discovery, are also steps toward a more democratic ML4Sci. Cloud-based AutoML platforms raise the abstraction barrier and lower the barrier of entry for scientists or other non-experts in the field of AI. The ultimate dream is to be able to upload a large dataset to the cloud and have it algorithmically design a specialized model with excellent generalization ability that is better than any human expert could have been designed. (Of course, explainability and interpretability are other, also important, problem specifications that still require significant work).
Computer Vision’s Overfitting Problem
AutoML papers like this one claim to discover novel, task-independent improvements to neural architectures. But they are evaluated on a narrow range of datasets, which were ImageNet and CIFAR for this particular paper. After almost a decade of work on improving performance the same set of benchmarks, might it be time to ask if the entire field of AI, like one giant population-based algorithm, is too narrowly focused, and thus overfitting, on the same set of benchmarks? Don’t get me wrong; standardized datasets are important to measure progress in a growing field, so long as they pose a difficult and relevant problem. And since the 2012 “ImageNet moment”, when Krizhevsky et. al. published their CNN paper, the performance on such computer vision datasets has become increasingly saturated, to the point where one might argue such datasets are no longer useful. Indeed, some might say that the CV field is overfitting to a small set of datasets, that are no longer difficult enough to justify being used as a benchmark. This is why we see new CV datasets like the Kannada-MNIST that aim to provide a more difficult challenge and introduce some novelty to the field.
This is where ML4Sci comes into play: ML4Sci offers a new set of difficult and relevant datasets that the field of computer vision has not yet seen, like a test set of datasets. I’m personally really curious to see if work like this, which proposes task-independent changes to training and other similar training and architecture tricks e.g. learning rate scheduling, really do show a performance boost on other datasets outside of CIFAR and ImageNet, potentially on a ML4Sci dataset! Oftentimes, ML4Sci is portrayed as a laggard field, borrowing the most well-tested strategies only after the AI community has already established them. But the benefits can actually go both ways: not only does ML4Sci offer new ideas to the AI community e.g. the Hamiltonian Neural Networks we covered in ML4Sci #4, but it also poses new problems that can help shape and serve as a test benchmark for work like this.
Standard spiel about tech + AI: AutoML-zero and this paper are both the work of Google researchers, led by Quoc V. Le, who’s published a number of seminal results in deep learning. Indeed, Google has been leading work on NAS since the seminal work by B. Zoph and Q. Le in 2017 on reinforcement learning for NAS. Since then, Google has been applying NAS to a variety of problems[1,2,3,4]. The prospect of a single tech company that has proprietary search algorithms that are able to construct neural architectures better than any human-designed one is rather concerning, as it would be another step towards their dominance in every field that touches AI, including ML4Sci.
For reference: it was also (different) Google researchers who came up with batch normalization. Google filed for and was recently granted a patent for batch normalization.
[pdf][Science Magazine Blog][automl-zero]
Inverse Photonic Design: Owen Miller’s PhD Thesis
Published Spring 2012
Ph.D theses are a gold mine for anyone looking to find a comprehensive, deeply technical introduction to a topic that goes beyond those found in journal papers. This is a thesis from Owen Miller titled “Photonic Design: From Fundamental Solar Cell Physics to Computational Inverse Design”, who was a student in Eli Yablanovitch’s group at UC Berkeley and now a professor at Yale. Someone recommended it to me awhile ago and I finally found a chance to read it - here’s some notes and thoughts.
Part I: The Physics of High-Efficiency Solar Cells
We’ll mostly skip this part, as it’s not relevant to ML4Sci. But for anyone interested in photovoltaics, this section provides a nice overview of the design challenges of solar. The main breakthrough of this section of the thesis is the counter-intuitive maxim that “A great solar cell also needs to be a great Light Emitting Diode”. It was this insight that allowed Eli Yablanovitch’s group to design a record-breaking GaAs solar cell with an efficiency of 28.9%.
Part II: Photonic Inverse Design
“Connecting structure to function has a long history of driving scientific progress…Understanding the relationship between a structure and its functionality can provide deep scientific understanding, generate new conceptual avenues, and enable breakthrough technologies” Chapter 1, Introduction
“When there has been little mathematical apparatus built up, scientists make progress through what could be called the Edisonian method: hypothesizing new structures or designs, then experimentally testing them. Once the foundational mathematics is understood, transition to a second phase can occur, in which new designs are intuited and perhaps tested computationally, but fundamentally the design space is imposed by the scientist. Finally, once computational design tools have been created, new designs can arrive from computational problem-solving” Chapter 1.2, Inverse Design
Significant progress has been made on solving forward problems e.g. “for a given geometry, what are the resulting fields and/or eigen-frequencies?”; for a given structure, what are its resulting mechanical properties (finite-element); for a given molecule, what are its chemical properties (Density Functional Theory), etc. But most scientists and engineers are interested in is the inverse problem e.g. “for a desired electromagnetic response, what geometry is needed?”; for a given stress-strain curve, what is an appropriate composite structure; for a given set of chemical properties, what is the molecule that will satisfy these constraints, etc. The problem formulation for inverse photonic design is an application of PDE-constrained optimization, the specific PDE’s for this problem being the Maxwell equations, as shown below, where F is some merit function (a.k.a. cost function). But the methods developed for one specific application generalize quite well, as PDE’s are ubiquitous in describing nature, making this work of interest for anyone who wants to design something that optimizes some physical response described by differential equations.

Rather than using traditional optimization algorithms, like evolutionary algorithms, Miller proposes using shape calculus to significantly decrease the number of simulations required, by exploiting the symmetry of Green’s function. I’ll leave out the gnarly math and refer readers to the thesis itself to find the technical treatment (Ch. 5). The proposed inverse design formulation was applied to optical cloaking (Ch. 6, see Fig. 6.6 below) and solar cell surface texturing (Ch. 7). Both of these applications exploit the “sweet spot” of photonic design, that is when the design scale is on the same length regime as the wavelength of light. It is at this length scale where the complexity explodes, the design space expands, and where inverse design is necessary. I’d be curious to see if this “sweet spot” of complexity exists in other fields, where complexity explodes in a certain regime, for which inverse design may be useful.

Some closing thoughts
Inverse design covers a wide spectrum of problems in engineering. As I mentioned earlier, any physical phenomena described by differential equations for which we want to optimize over falls under inverse design. More broadly, inverse problems require inverting non one-way functions e.g. Schrodinger equation, Navier Stokes, MRI phase reconstruction, etc. It’s something we’ve covered in this newsletter for crystallography, diffractive gratings, and fluid mechanics. One benefit of studying all these different papers is that nature speaks the same language at all length scales. By noticing similarities across different fields, we can borrow approaches; inverse photonic design based on Maxwell’s PDE’s can be generalized to other differential equation optimization schemes.
In the News
Facebook creates a virtual world filled with bot’s trained to mimic real users that runs on Facebook’s actual infrastructure, to test how different restrictions might affect user interaction. Westworld anybody? [h/t Import AI #193]
NVIDIA opens-sources project to standardize healthcare imaging processing and model training, in collaboration with King’s College London [NVIDIA blog]
We mentioned Google’s study on predicting diabetic retinopathy from retinal photographs with deep learning in ML4Sci #5. TechCrunch provides a nice synopsis of recent Google reports of the performance of this AI system being deployed in Thailand and difficulties it faced out in the real-world. Good reminder that despite the hype of medical AI, the real-world is still fraught with human interface and data clean-up challenges.
Thanks for Reading!
I hope you’re as excited as I am about the future of machine learning for solving exciting problems in science. You can find the archive of all past issues here and click here to subscribe to the newsletter.
Have any questions, feedback, or suggestions for articles? Contact me at ml4science@gmail.com or on Twitter @charlesxjyang